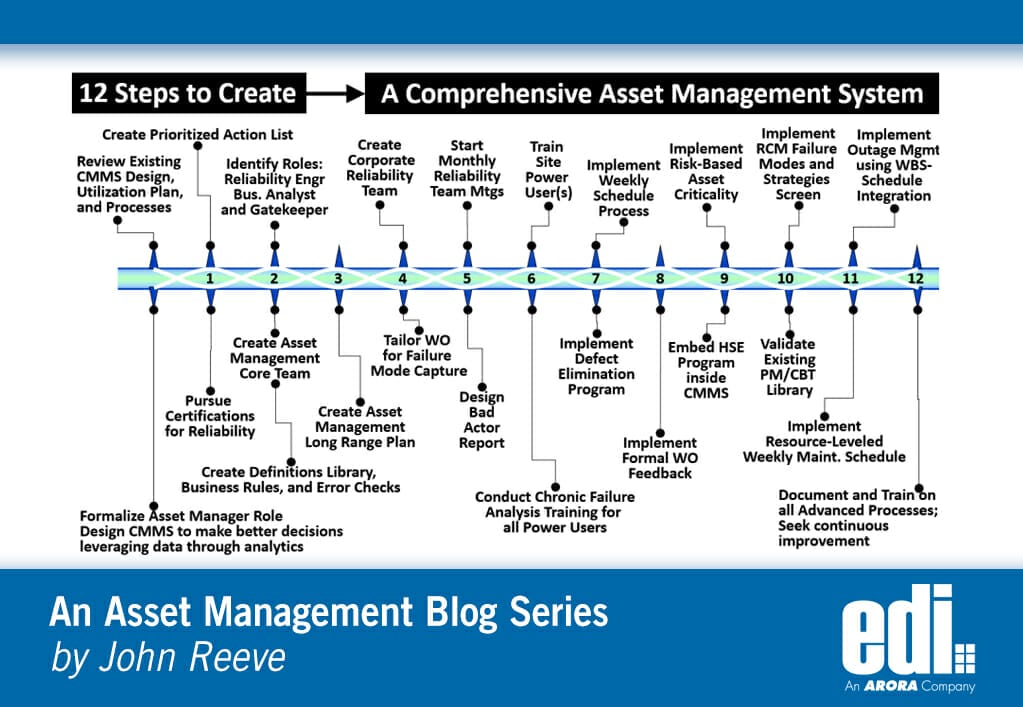

The above chronology emphasizes advanced processes which enhance asset reliability, workforce productivity, and job safety. The goal, as always, is to work on the right asset, using the right strategy, in the safest manner, at the right time, by the right resource, for the least cost. But installing software, even a best-of-breed product, will not get you there without a long-range plan and careful thought of the endgame.
The Asset Manager position (or similar) identifies the vision for excellence. He/she is responsible for the vision/mission statement, SAMP, a CMMS utilization plan, and a long-range plan, plus the implementation of standards across the organization. The Asset Manager would provide a roadmap for the creation of a true knowledge base, the use of analytical reports to manage by exception, and continuous improvement therein.
Planning, in this case, means schedule. The only perfect schedule is one that is 100% done. But to not have a schedule opens the door to poor craft coordination, not working the critical path, poor scope control, and increased risk. Dates might be missed, but at least you know what to work on, in what order, and by whom. Maybe the best reason to have a long-range plan is to not forget things, plus, it makes a great conversation starter!



