NEWS AND INSIGHT
Categories
Tags
Recent Posts
Implementing a Reliability-Based Maintenance Program

Advanced Processes Offer the Greatest Potential ROI
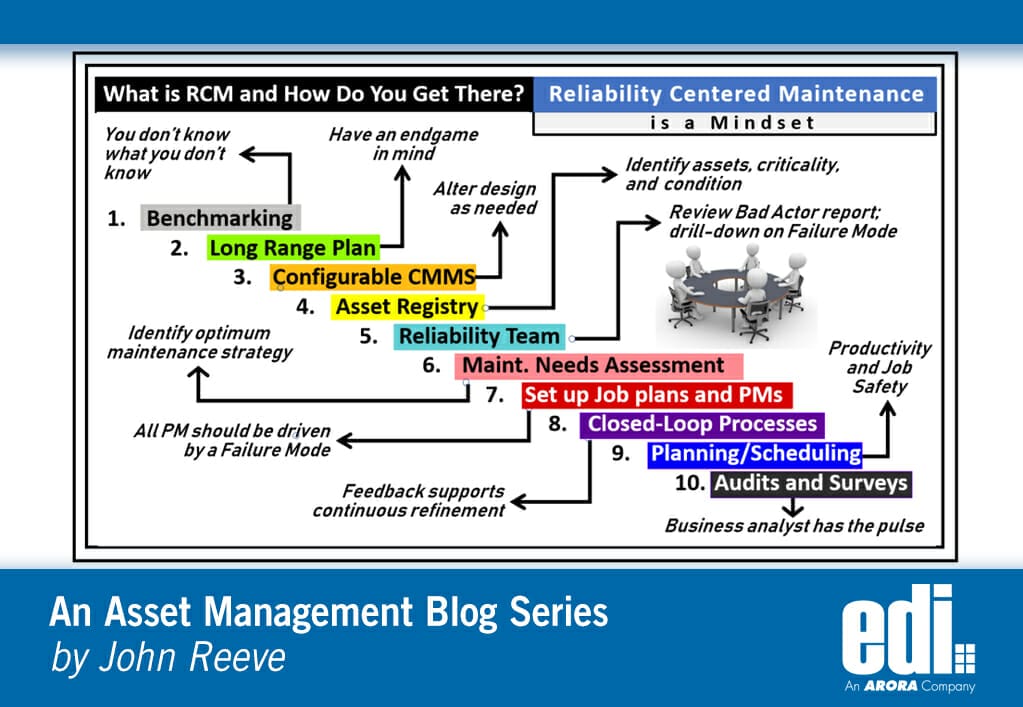
The above chronology emphasizes advanced processes which enhance asset reliability, workforce productivity, and job safety. The goal, as always, is to work on the right asset, using the right strategy, in the safest manner, at the right time, by the right resource, for the least cost. But installing software, even a best-of-breed product, will not get you there without a long-range plan and careful thought of the endgame.
The Asset Manager Role is Key
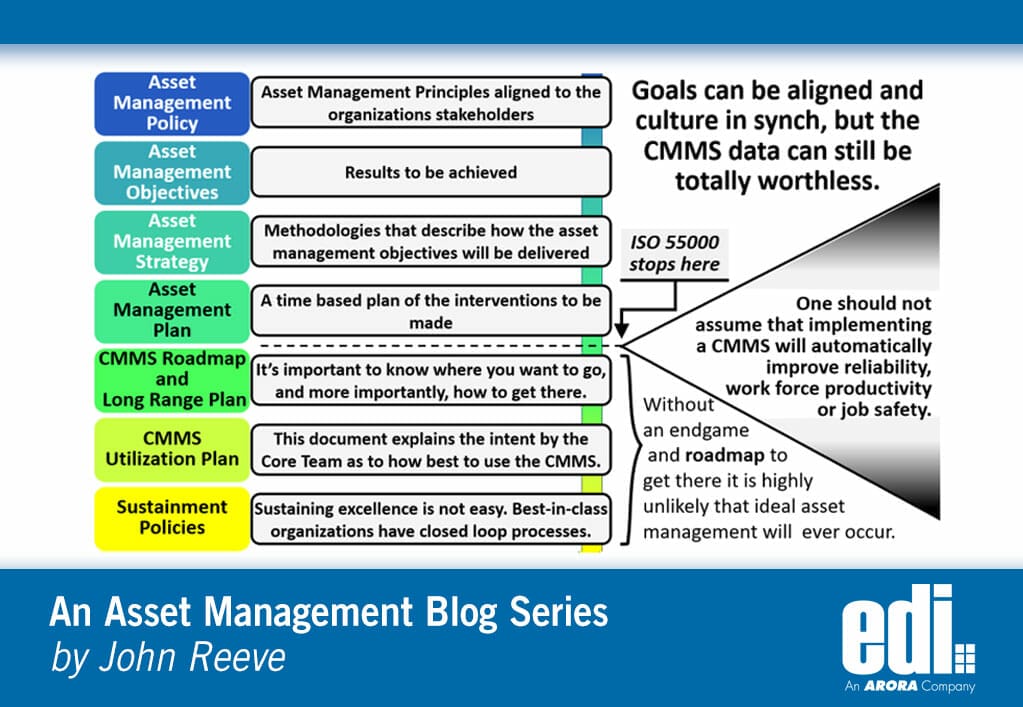
The Asset Manager position (or similar) identifies the vision for excellence. He/she is responsible for the vision/mission statement, SAMP, a CMMS utilization plan, and a long-range plan, plus the implementation of standards across the organization. The Asset Manager would provide a roadmap for the creation of a true knowledge base, the use of analytical reports to manage by exception, and continuous improvement therein.
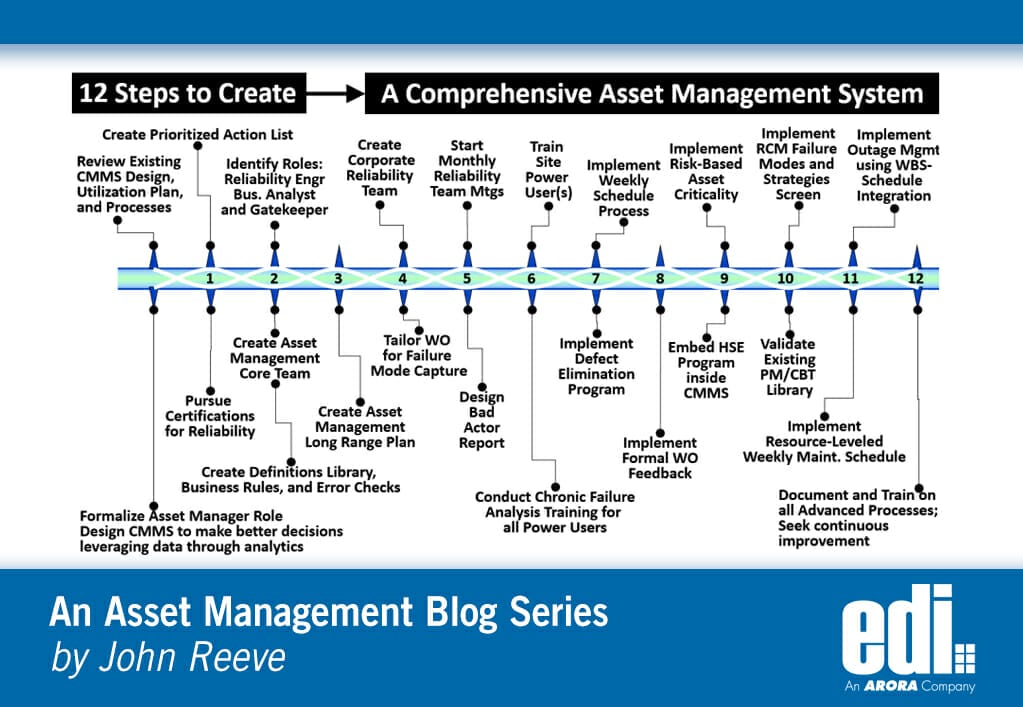
20 Steps to Better Asset Management
- The Asset Manager introduces a Reliability-Based Maintenance Program across the entire portfolio. All plants would be required to adhere to these standards.
- The review team (led by the Asset Manager) will conduct an AS-IS assessment of the current CMMS design, create SAMP and utilization plan, build-out supporting process and roles, review KPIs and analytical report capability, and assess overall culture and buy-in to asset management.
- The Asset Manager technical specialist will conduct technical training of CMMS support staff depending on the assessment. Also, make sure the CMMS admin staff is not under-utilizing any power features (e.g. auto part reorder at ROP; the Autosparepartadd flag; PM-to-WO generation cron; and SR-to-WO conversion).
- The Asset Manager will work with HR to establish positions/roles for reliability engineer, business analyst, and gatekeeper. The CMMS database and accuracy therein has been questioned since the dark ages. It’s time to do something about it. Therefore, I strongly believe in the role of gatekeeper. This person would (1) process/dispatch urgent work, (2) perform WO accuracy/quality grading by submitter, (3) provide a WO relative ranking of importance, lead craft, and rough estimate, and (4) provide WO completions review to include failure mode and WO feedback. A business analyst would interview all groups involved with asset management, document essential analytical reports, and take these outputs to the core team to make sure the voice of “working level is heard.”
- The Asset Manager will create an asset management core team. They will establish a definitions library, business rules, and activate data quality error checks. They will also begin tracking a prioritized action list and pursue on-going benchmarking in search of continuous improvement.
- The Asset Manager would lead group discussions on the creation of a resource-leveled long-range plan.
- Create a reliability team with charter and purpose. Instruct them to design the bad actor report with drill-down on failure mode and identify RCA trigger points. Combining powerful analytics with meaningful failure data about health/performance, management can make smarter decisions, increase reliability, and reduce O&M costs.
- Set up work order main for failure mode capture (failed component + component problem + cause) as validated fields.
- Start monthly reliability team meetings and run the bad actor report with multiple options for extracting the Top 10, including average annual maintenance cost divided by replacement cost. Drill-down on failure mode (cause) and take corrective action.
- Identify site power users. Get their input on problems and their suggestions.
- Implement chronic failure analysis training for all sites and power users.
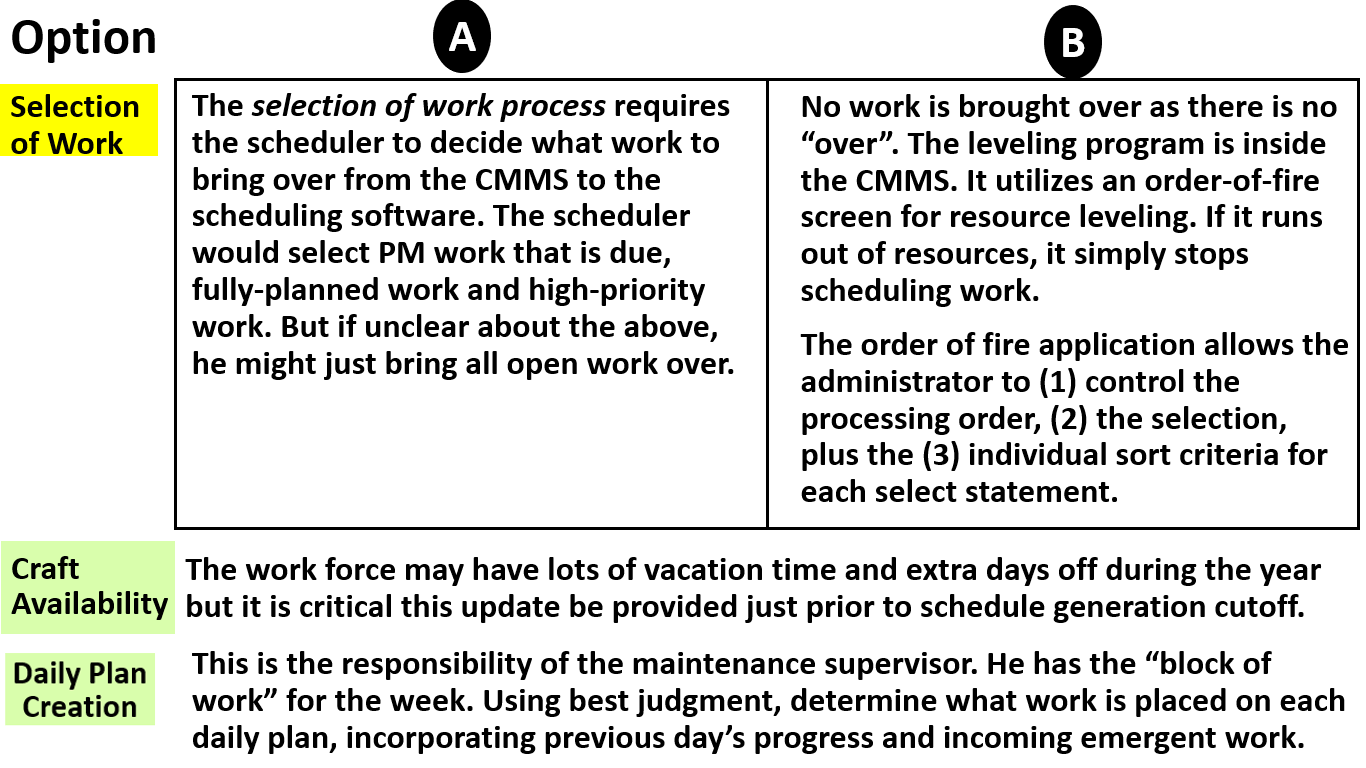
- Evaluate the planning process and backlog management. Implement a resource-leveled, weekly maintenance schedule (inside the CMMS) using a risk-based work order prioritization matrix.
- Implement a defect elimination program.
- Implement formal work order feedback to include capture of maintainability, safety issues, ergonomics, design flaws, PM strategy & frequency refinements, missing asset, and missing failure codes.
- Design/build screen for capturing risk-based asset criticality.
- Embed safety (HSE) program into the reliability-based maintenance program.
- Design/build RCM failure modes and strategies screen for storing analysis results inside CMMS and create a living program.
- Begin the on-going process of validating the existing PM/CBT program using RCM/PMO analysis and WO feedback.
- Implement integrated project cost tracking for STO using WBS cost accounts. Provide scheduling software which facilitates total float calculations, progressing, automatic resource leveling, logic bar charts, histograms, and network diagrams.
- Create reliability leaders throughout the organization (e.g. ReliabilityWeb CRL program)
The Purpose of a Plan
Planning, in this case, means schedule. The only perfect schedule is one that is 100% done. But to not have a schedule opens the door to poor craft coordination, not working the critical path, poor scope control, and increased risk. Dates might be missed, but at least you know what to work on, in what order, and by whom. Maybe the best reason to have a long-range plan is to not forget things, plus, it makes a great conversation starter!